Agentic RAG가 기존 RAG와 무엇이 다른지, 질문 분해·다중 검색·충분성 검사·재검색 루프가 어떻게 동작하는지 실무 관점에서 쉽게 정리합니다.
Agentic RAG란? 한 번 검색하고 끝나는 RAG에서 ‘부족하면 다시 찾는 AI’로
AI에게 회사 문서, 법령, 논문, 고객 기록처럼 모델이 원래 알지 못하는 자료를 검색하게 한 뒤 답변을 생성하는 방식을 RAG(Retrieval-Augmented Generation)라고 합니다.
RAG는 LLM의 환각을 줄이고 최신 정보나 내부 데이터를 답변에 반영하는 데 매우 유용합니다. 하지만 실제 업무 질문은 생각보다 단순하지 않습니다.
예를 들어 사용자가 다음과 같이 질문했다고 해보겠습니다.
“프로젝트 X에 사용된 서버의 사양과 최근 장애 원인, 담당 팀의 후속 조치까지 알려줘.”
필요한 정보가 한 문서에 모두 들어 있다면 일반적인 RAG로도 충분합니다. 그러나 실제 조직에서는 정보가 다음처럼 흩어져 있을 가능성이 큽니다.
- 프로젝트 문서에는 서버 ID만 기록되어 있다.
- 서버 사양은 자산 관리 데이터베이스에 있다.
- 장애 원인은 모니터링 로그와 장애 보고서에 있다.
- 후속 조치는 이슈 트래커에 있다.
기존 RAG는 첫 번째 검색에서 프로젝트 문서를 찾은 뒤, 그 문서에 적힌 서버 ID를 이용해 다른 데이터베이스를 다시 검색해야 한다는 사실을 알아차리지 못할 수 있습니다.
이 문제를 해결하려는 접근이 바로 Agentic RAG(에이전틱 RAG) 입니다.
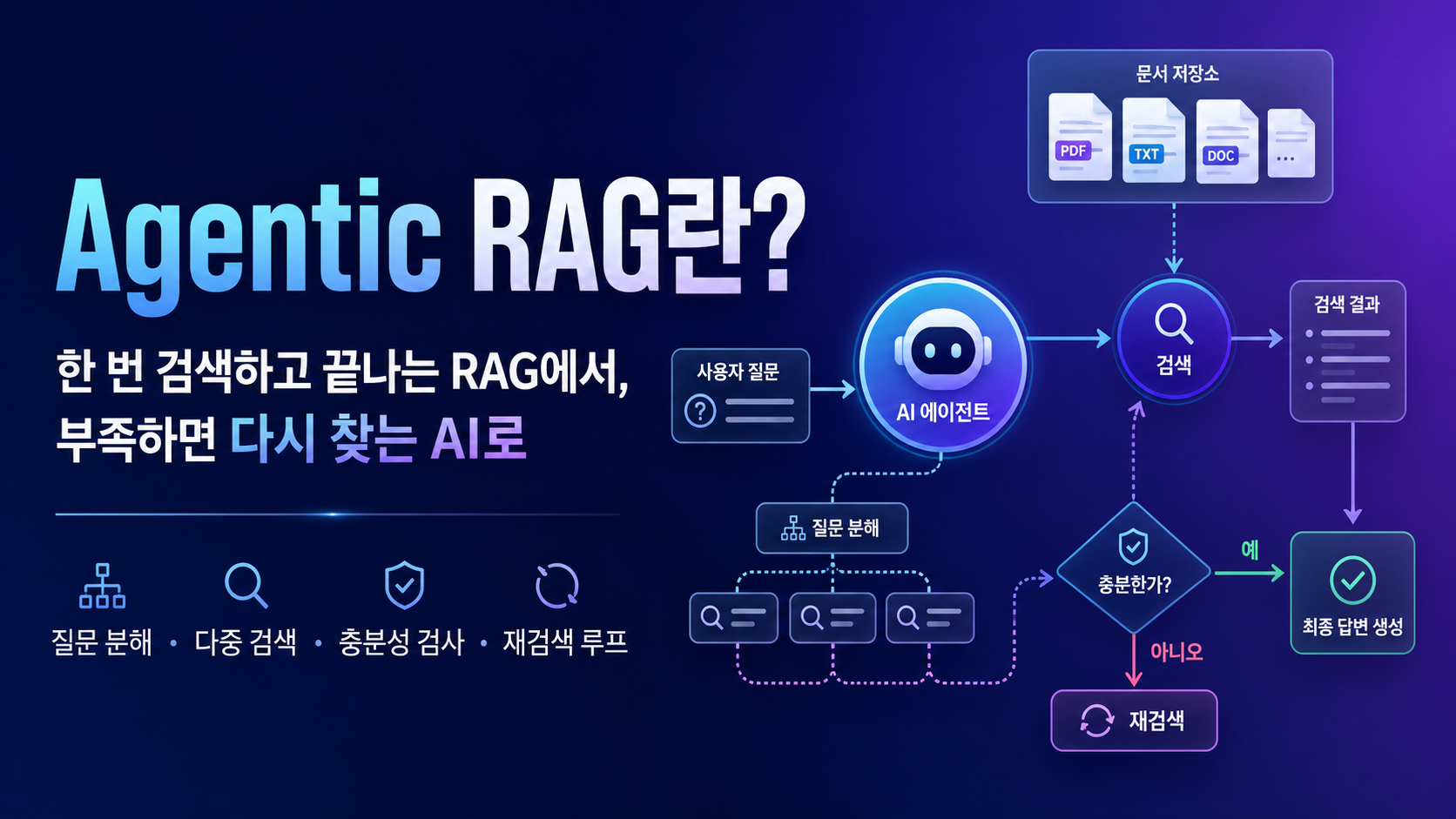
먼저 결론: Agentic RAG는 ‘검색 기능’보다 ‘검색을 운영하는 판단 루프’에 가깝습니다
Agentic RAG를 한 문장으로 정리하면 다음과 같습니다.
질문을 분석하고, 검색 계획을 세우고, 여러 데이터 소스를 조회한 뒤, 정보가 부족하면 무엇이 빠졌는지 판단하여 다시 검색하는 RAG 시스템
일반적인 RAG가 다음 구조라면,
질문 → 검색 → 관련 문서 → LLM 답변Agentic RAG는 다음처럼 동작합니다.
질문
↓
질문 분석·작업 분해
↓
검색 계획 수립
↓
여러 소스 검색
↓
현재 정보로 답할 수 있는가?
├─ 예 → 근거를 종합해 최종 답변
└─ 아니오 → 빠진 정보 분석 → 검색어 수정 → 다시 검색핵심은 에이전트가 단순히 검색 도구를 호출하는 것이 아닙니다.
언제 검색해야 하는지, 어디를 검색해야 하는지, 현재 확보한 정보가 충분한지, 언제 멈춰야 하는지를 판단하는 구조가 포함되어야 합니다.

기존 RAG와 Agentic RAG의 차이
| 비교 항목 | 일반적인 RAG | Agentic RAG |
|---|---|---|
| 검색 횟수 | 보통 1회 | 필요에 따라 반복 |
| 질문 처리 | 원문 그대로 검색 | 질문을 여러 하위 질문으로 분해 |
| 데이터 소스 | 단일 인덱스 중심 | 여러 코퍼스·DB·API로 라우팅 |
| 검색어 | 최초 검색어 고정 | 결과에 따라 검색어 재작성 |
| 정보 부족 판단 | 모델이 그대로 답하거나 포기 | 충분성 검사 단계에서 누락 정보 탐지 |
| 종료 조건 | 검색 결과를 받으면 종료 | 필요한 근거가 충분할 때 종료 |
| 장점 | 빠르고 단순함 | 복잡한 멀티홉 질문에 강함 |
| 단점 | 부분 답변과 누락 가능성 | 비용·지연 시간·운영 복잡도 증가 |
여기서 가장 중요한 차이는 멀티홉 검색(Multi-hop Retrieval) 입니다.
멀티홉 검색은 한 번의 검색 결과가 다음 검색의 단서가 되는 구조입니다.
“프로젝트 X의 서버 사양은?”
1차 검색: 프로젝트 X 문서
→ 서버 ID: srv-prod-17 발견
2차 검색: 자산 DB에서 srv-prod-17 조회
→ CPU, RAM, 리전, 운영체제 정보 발견
최종 답변 생성첫 번째 검색만으로는 정답이 나오지 않지만, 검색 결과에서 새로운 단서를 얻어 두 번째 검색을 수행하면 답에 도달할 수 있습니다.
Google이 공개한 Agentic RAG에서 주목할 부분
Google Research는 2026년 6월 5일 Gemini Enterprise Agent Platform의 Agentic RAG 구조를 공개했습니다.
공개된 구조에는 다음과 같은 역할이 포함됩니다.
1. 오케스트레이터(Orchestrator)
사용자 요청을 보고 단일 검색으로 처리할 수 있는지, 여러 단계가 필요한지를 판단합니다.
복잡한 질문이라면 하위 작업으로 나누고 다른 에이전트에게 전달합니다.
2. 플래너 에이전트(Planner Agent)
어떤 순서로 어느 데이터 소스를 검색할지 계획합니다.
예를 들어 예산과 일정이 함께 필요한 질문이라면 다음처럼 경로를 만들 수 있습니다.
재무 데이터베이스 검색
↓
프로젝트 관리 시스템 검색
↓
두 결과의 프로젝트 ID와 기간을 정렬3. 쿼리 리라이터(Query Rewriter)
사람이 입력한 모호한 질문을 검색 시스템이 처리하기 쉬운 형태로 바꿉니다.
원래 질문:
“프로젝트 X는 지금 어떻게 되고 있어?”
재작성된 검색어:
- “프로젝트 X 2026년 2분기 상태 보고서”
- “프로젝트 X 현재 지연 원인”
- “프로젝트 X 미해결 위험 요소”4. 검색 팬아웃(Search Fanout)
여러 검색어와 데이터 소스에 검색을 병렬로 수행합니다.
문서 검색, SQL 데이터베이스, 로그 시스템, API, 벡터 데이터베이스가 각각 하나의 검색 대상이 될 수 있습니다.
5. 충분한 컨텍스트 에이전트(Sufficient Context Agent)
이 구조의 핵심입니다.
현재 검색된 자료만으로 사용자의 질문에 정확하고 근거 있는 답변을 만들 수 있는지 검사합니다.
단순히 “정보가 부족하다”고만 판단하는 것이 아니라 다음 내용을 구조적으로 출력해야 합니다.
{
"sufficient": false,
"covered": [
"퇴원 약물",
"식이 제한"
],
"missing": [
"입원 기간 중 알레르기 반응"
],
"next_queries": [
"입원 기록 발진 알레르기 이상 반응",
"adverse event allergy rash"
]
}이 결과를 받은 쿼리 리라이터는 누락된 정보를 겨냥해 새로운 검색어를 만들고 다시 검색합니다.
6. 종합 에이전트(Synthesis Agent)
필요한 정보가 충분하다고 판정되면 여러 출처의 내용을 하나의 답변으로 정리합니다.
최종 답변에는 가능하면 다음 요소가 포함되어야 합니다.
- 핵심 결론
- 근거 문서 또는 데이터 출처
- 서로 충돌하는 정보
- 확인되지 않은 부분
- 검색 시점
- 사용한 조건과 예외

Agentic RAG 전체 동작 흐름
Agentic RAG의 구조를 조금 더 구체적으로 표현하면 다음과 같습니다.
┌─────────────────────┐
│ 사용자 질문 │
└──────────┬──────────┘
↓
┌─────────────────────┐
│ 오케스트레이터 │
│ 복잡도·의도·권한 판단 │
└──────────┬──────────┘
↓
┌─────────────────────┐
│ 플래너 에이전트 │
│ 질문 분해·검색 순서 │
└──────────┬──────────┘
↓
┌─────────────────────┐
│ 쿼리 리라이터 │
│ 검색용 하위 질문 생성 │
└──────────┬──────────┘
↓
┌──────────────────────────────────┐
│ 검색 라우터 / 팬아웃 │
│ 벡터 DB · SQL · 문서 · API · 로그 │
└──────────┬───────────────────────┘
↓
┌─────────────────────┐
│ 검색 결과·초안 생성 │
└──────────┬──────────┘
↓
┌────────────────────────────┐
│ 충분한 컨텍스트 에이전트 │
│ 답변 가능? 누락 정보는 무엇? │
└───────┬─────────────┬──────┘
│ 충분 │ 부족
↓ ↓
┌───────────────┐ ┌────────────────┐
│ 종합·출처 표시 │ │ 검색어 수정 │
│ 최종 답변 생성 │ │ 추가 검색 반복 │
└───────────────┘ └───────┬────────┘
└── 검색 단계로 복귀왜 ‘충분한 컨텍스트’ 판단이 중요한가?
RAG 시스템의 오류는 크게 두 종류로 나눌 수 있습니다.
1. 검색 결과는 충분했지만 LLM이 제대로 사용하지 못한 경우
필요한 근거가 검색 결과에 있는데도 모델이 놓치거나 잘못 해석한 경우입니다.
이 문제는 프롬프트, 모델 성능, 컨텍스트 배열, 리랭킹, 출력 검증을 개선해야 합니다.
2. 애초에 검색 결과가 부족한 경우
필요한 문서가 검색되지 않았거나, 여러 데이터 소스 중 일부만 조회한 경우입니다.
이 상태에서 LLM에게 답을 강요하면 모델이 추측을 섞을 가능성이 커집니다.
Agentic RAG의 충분성 검사는 이 두 문제를 구분하려는 장치입니다.
정답을 못 만든 이유가
“모델이 문서를 잘못 읽어서”인지,
“정답에 필요한 문서 자체가 없어서”인지
먼저 판단해야 합니다.이 구분이 없으면 검색 품질과 생성 품질을 따로 개선하기 어렵습니다.
공개된 실험 결과는 어떻게 봐야 할까?
Google Research는 자사의 Agentic RAG가 표준 RAG보다 사실성 데이터셋 정확도를 최대 34% 개선했다고 설명했습니다.
또한 FramesQA 기반 실험에서는 다음 조건을 사용했습니다.
- 질의 824개
- PDF 문서 2,676개
- 관련 코퍼스 1개와 방해용 데이터셋 3개
- 플래너가 네 개 후보 중 검색할 코퍼스를 선택
- LLM-as-a-judge 방식으로 정답과 시스템 응답 비교
Google이 공개한 결과에 따르면 교차 코퍼스 환경에서 질문의 90.1%에 정확히 답했고, 단일 코퍼스와 교차 코퍼스 구성의 평균 지연 시간 차이는 3% 이내였습니다.
다만 이 숫자를 모든 RAG 프로젝트에 그대로 적용해서는 안 됩니다.
이 수치는 Google의 모델, 검색 엔진, 리랭커, 데이터셋, 평가 방식이 결합된 결과입니다.
실제 성능은 다음 요소에 따라 크게 달라집니다.
- 문서 품질과 최신성
- 청크 분할 방식
- 임베딩 모델
- 검색 인덱스
- 메타데이터 설계
- 리랭커 성능
- 질문 분해 품질
- 에이전트의 종료 조건
- 평가 데이터셋
- 도메인 전문성
따라서 “Agentic RAG를 쓰면 정확도가 34% 오른다”가 아니라, 복잡한 검색 문제에서 반복 검색과 충분성 검사가 성능을 개선할 가능성을 보여준 결과로 이해하는 편이 정확합니다.
모든 질문에 Agentic RAG가 필요한 것은 아닙니다
Agentic RAG는 강력하지만 항상 좋은 선택은 아닙니다.
일반 RAG가 더 적합한 경우
- FAQ처럼 질문과 답변이 단순하다.
- 한 문서나 한 코퍼스에서 답을 찾을 수 있다.
- 응답 속도가 매우 중요하다.
- 데이터 규모가 작고 구조가 명확하다.
- 검색 비용을 최소화해야 한다.
- 검색 정확도가 이미 충분히 높다.
Agentic RAG가 유리한 경우
- 여러 문서의 내용을 연결해야 한다.
- 한 검색 결과가 다음 검색의 단서가 된다.
- 데이터가 여러 시스템에 흩어져 있다.
- 질문에 조건과 예외가 많다.
- 누락 없는 답변이 중요하다.
- 답변의 근거와 검색 과정을 감사해야 한다.
- 법률, 의료, 금융, 기업 지식 검색처럼 신뢰성이 중요하다.
가장 실용적인 설계는 모든 요청을 Agentic RAG로 보내는 것이 아니라 질문 복잡도에 따라 경로를 나누는 것입니다.
사용자 질문
↓
복잡도 분류
├─ 단순 질문 → 일반 RAG
├─ 복합·멀티홉 질문 → Agentic RAG
└─ 근거 부족·고위험 질문 → 사람 검토 또는 답변 보류이를 Adaptive RAG 또는 라우팅 기반 RAG라고 부르기도 합니다.
직접 구현할 때의 최소 구성
처음부터 여러 에이전트와 데이터베이스를 모두 붙이면 디버깅이 매우 어려워집니다.
MVP는 다음 다섯 단계만 구현하는 것이 좋습니다.
1단계. 기존 RAG의 검색 품질부터 측정하기
먼저 일반 RAG에서 다음 지표를 수집합니다.
- Recall@K: 정답 문서가 상위 K개 안에 포함되는가?
- MRR: 정답 문서가 얼마나 앞에 나타나는가?
- Faithfulness: 답변이 검색 근거에 충실한가?
- Citation Accuracy: 인용한 출처가 실제 주장을 뒷받침하는가?
- Answer Completeness: 질문의 모든 요구 사항을 답했는가?
기본 검색기가 약하면 에이전트를 추가해도 잘못된 검색을 여러 번 반복할 뿐입니다.
2단계. 질문 분해기 추가하기
복합 질문을 독립적인 하위 질문으로 나눕니다.
원래 질문:
“2025년 매출이 가장 많이 증가한 제품과 그 원인,
관련 고객 불만 변화까지 설명해줘.”
하위 질문:
1. 2024년과 2025년 제품별 매출은?
2. 증가액이 가장 큰 제품은?
3. 해당 제품의 판매 증가 원인은?
4. 같은 기간 고객 불만 건수와 유형은 어떻게 변했는가?3단계. 충분성 평가기를 추가하기
검색 결과와 질문을 비교해 다음을 출력하도록 합니다.
from dataclasses import dataclass
@dataclass(frozen=True)
class SufficiencyResult:
sufficient: bool
covered: list[str]
missing: list[str]
next_queries: list[str]여기서 중요한 것은 단순 점수 하나보다 누락된 항목과 다음 검색어를 구조화해 반환하는 것입니다.
4단계. 반복 횟수와 비용 한도 설정하기
무한 검색 루프를 막아야 합니다.
MAX_ROUNDS = 3
MAX_QUERIES_PER_ROUND = 5
MAX_CONTEXT_CHUNKS = 30종료 조건도 명확히 정의해야 합니다.
- 충분성 평가가 true
- 최대 반복 횟수 도달
- 새로 검색된 문서가 없음
- 같은 검색어가 반복됨
- 비용 또는 시간 예산 초과5단계. 검색 과정 전체를 로그로 남기기
최종 답변만 저장하면 실패 원인을 알기 어렵습니다.
최소한 다음 항목을 기록해야 합니다.
request_id
원본 질문
분해된 하위 질문
선택된 데이터 소스
각 검색어
검색된 문서 ID와 점수
충분성 판정
누락 정보
반복 횟수
최종 인용 출처
전체 지연 시간
토큰·API 비용구현 골격 예시
아래 코드는 특정 프레임워크에 종속되지 않은 Agentic RAG의 기본 흐름입니다.
from dataclasses import dataclass
from typing import Protocol
@dataclass(frozen=True)
class Document:
source_id: str
text: str
score: float
@dataclass(frozen=True)
class SufficiencyResult:
sufficient: bool
missing: list[str]
next_queries: list[str]
class Retriever(Protocol):
def search(self, query: str, limit: int = 5) -> list[Document]:
...
class Reasoner(Protocol):
def decompose(self, question: str) -> list[str]:
...
def evaluate_sufficiency(
self,
question: str,
documents: list[Document],
) -> SufficiencyResult:
...
def synthesize(
self,
question: str,
documents: list[Document],
) -> str:
...
def run_agentic_rag(
question: str,
retriever: Retriever,
reasoner: Reasoner,
*,
max_rounds: int = 3,
documents_per_query: int = 5,
) -> str:
queries = reasoner.decompose(question)
collected: dict[str, Document] = {}
for _round in range(max_rounds):
for query in queries:
for document in retriever.search(
query,
limit=documents_per_query,
):
collected[document.source_id] = document
documents = list(collected.values())
result = reasoner.evaluate_sufficiency(
question,
documents,
)
if result.sufficient:
return reasoner.synthesize(question, documents)
if not result.next_queries:
break
queries = result.next_queries
return (
"검색된 근거만으로는 질문에 완전하게 답하기 어렵습니다. "
f"추가로 필요한 정보: {result.missing}"
)실제 서비스에서는 여기에 다음 기능이 추가됩니다.
- 벡터 검색과 키워드 검색을 결합한 하이브리드 검색
- 메타데이터 필터
- 리랭킹
- 데이터 소스별 권한 검사
- 중복 문서 제거
- 프롬프트 인젝션 방어
- 출처 인용 검증
- 캐시
- 비동기 병렬 검색
- 추적·관찰 가능성(Observability)
실무에서 가장 자주 발생하는 실패 6가지
1. 질문 분해가 잘못되어 검색 범위가 더 넓어짐
복잡한 질문을 무조건 많이 나누면 관련 없는 검색이 늘어납니다.
하위 질문은 원래 질문의 정답을 구성하는 데 필요한 항목만 포함해야 합니다.
2. 충분성 평가기가 너무 쉽게 “충분하다”고 판정함
부분 답변을 완전한 답변으로 착각하면 재검색 루프의 의미가 사라집니다.
질문의 요구 항목을 체크리스트로 만들고 각 항목의 근거 존재 여부를 검사해야 합니다.
3. 반대로 계속 “부족하다”고 판정해 무한 검색함
필요한 정보가 데이터베이스에 존재하지 않을 수도 있습니다.
최대 반복 횟수, 시간 예산, 새 문서 발견 여부를 종료 조건으로 사용해야 합니다.
4. 여러 에이전트를 붙였지만 모두 같은 인덱스만 검색함
에이전트 수가 많다고 멀티소스 검색이 되는 것은 아닙니다.
각 데이터 소스의 역할과 설명, 접근 권한, 검색 인터페이스를 명확히 정의해야 합니다.
5. 답변 정확도만 측정하고 비용과 지연 시간을 측정하지 않음
Agentic RAG는 검색과 LLM 호출이 늘어날 수 있습니다.
정확도뿐 아니라 다음 지표를 함께 봐야 합니다.
정확도 향상
추가 검색 횟수
평균 응답 시간
P95 지연 시간
질문당 비용
재검색 성공률
불필요한 재검색 비율6. 에이전트가 검색한 문서를 그대로 신뢰함
검색된 문서에 잘못된 정보나 프롬프트 인젝션이 포함될 수 있습니다.
검색 결과는 명령이 아니라 검증해야 할 데이터로 취급해야 합니다.
법령·사내 문서·고객 지원 시스템에 적용한다면
법령 검색
사용자 질문
→ 적용 법률 분야 분류
→ 관련 법률 검색
→ 위임 법령·시행령·시행규칙 검색
→ 조문 간 인용 관계 추적
→ 개정일·시행일 확인
→ 판례·행정해석 필요 여부 판단
→ 근거가 충분할 때 답변단일 조문만 검색하는 방식보다 법률의 계층 구조와 개정 이력을 따라가는 검색 루프가 중요합니다.
사내 지식 검색
프로젝트 문서
+ 이슈 트래커
+ 회의록
+ 소스 코드
+ 운영 로그
+ 자산 DB플래너가 질문에 따라 필요한 시스템만 선택하고 결과를 연결할 수 있습니다.
고객 지원
고객 문의
→ 제품·버전 식별
→ 매뉴얼 검색
→ 알려진 장애 검색
→ 고객 계정 상태 조회
→ 해결 가능 여부 판정
→ 상담원 이관 또는 답변단, 개인정보와 계정 정보가 포함되므로 데이터 소스별 권한 검사가 반드시 필요합니다.
Agentic RAG 도입 체크리스트
아래 항목 중 여러 개가 해당될 때 도입을 검토할 만합니다.
- 한 번의 검색으로 답이 나오지 않는 질문이 많다.
- 정보가 여러 데이터베이스와 문서 시스템에 흩어져 있다.
- 부분 답변이나 누락이 실제 업무 문제로 이어진다.
- 검색 과정과 근거를 추적해야 한다.
- 질문 유형별 평가 데이터셋을 만들 수 있다.
- 검색·LLM 호출 비용을 측정할 수 있다.
- 데이터 소스별 권한 체계를 적용할 수 있다.
- 실패 시 답변을 보류하거나 사람에게 넘길 수 있다.
반대로 평가 데이터도 없고 기본 RAG의 검색 품질도 측정하지 않은 상태라면, Agentic RAG보다 먼저 문서 정제, 청크 설계, 메타데이터, 하이브리드 검색, 리랭킹을 개선하는 편이 효과적일 수 있습니다.
마무리
Agentic RAG의 본질은 에이전트 수를 늘리는 데 있지 않습니다.
핵심은 다음 세 가지입니다.
- 복잡한 질문을 검색 가능한 단위로 분해한다.
- 현재 근거가 질문에 답하기 충분한지 검사한다.
- 부족한 정보가 무엇인지 파악해 표적 검색을 반복한다.
기존 RAG가 “관련 문서를 한 번 찾아 LLM에게 전달하는 시스템”이라면, Agentic RAG는 “정답에 필요한 근거가 모일 때까지 검색 과정을 계획하고 조정하는 시스템”입니다.
다만 반복 검색은 비용과 지연 시간을 증가시킬 수 있으므로 모든 질문에 적용해서는 안 됩니다.
가장 현실적인 접근은 단순 질문은 일반 RAG로 빠르게 처리하고, 복합·멀티홉 질문만 Agentic RAG 경로로 보내는 것입니다.
더 많은 에이전트가 더 좋은 RAG를 만드는 것이 아닙니다.
무엇이 부족한지 알고, 필요한 근거를 정확히 다시 찾는 시스템이 더 좋은 RAG를 만듭니다.
참고 자료
Google Research, “Unlocking dependable responses with Gemini Enterprise Agent Platform’s Agentic RAG”
https://research.google/blog/unlocking-dependable-responses-with-gemini-enterprise-agent-platforms-agentic-rag/Google Cloud Documentation, “RAG Engine Cross Corpus Retrieval”
https://docs.cloud.google.com/gemini-enterprise-agent-platform/build/rag-engine/cross-corpus-retrievalGoogle Research, “Sufficient Context: A New Lens on Retrieval Augmented Generation Systems”
https://research.google/pubs/sufficient-context-a-new-lens-on-retrieval-augmented-generation-systems/PyTorchKR, “Google Research가 공개한 Agentic RAG”
https://discuss.pytorch.kr/t/google-research-agentic-rag/10599
이 글은 2026년 6월 15일 기준 공개 자료를 바탕으로 작성했습니다.
Google Cloud의 Cross-Corpus Retrieval 관련 기능은 공개 미리보기 상태이므로 실제 도입 전 최신 문서, 지원 리전, 요금, 할당량과 보안 제한을 다시 확인해야 합니다.
'AI & IT > 유용한 AI 지식들📚' 카테고리의 다른 글
| 긴 컨텍스트 창을 믿지 마세요: AI 코딩 에이전트가 대화를 길게 할수록 실수하는 이유! (5) | 2026.06.15 |
|---|
